Courseraオンライン講座の機械学習コースを
直感的な理解を優先して、ゆるーく まとめてます。
正確には公式サイトを参照して下さい。
[MachineLearning Week1](https://www.coursera.org/learn/machine-learning/home/week/1)
## Gradient Descent For Linear Regression

ここまでに説明してきた線形回帰の目的関数 $J(\theta_0, \theta_1)$ は、
パラメータ二つで、プロットすると
サラダボウルやハンモックみたいな形になります。
目的関数を最小化するということは、
このハンモックの底を見つけるということになります。

仮説$h_\theta(x)$の直線関数を
与えられた学習データに対して、
最小の誤差になるように配置するということは、
目的関数 $J(\theta_0, \theta_1)$を最小化することになります。

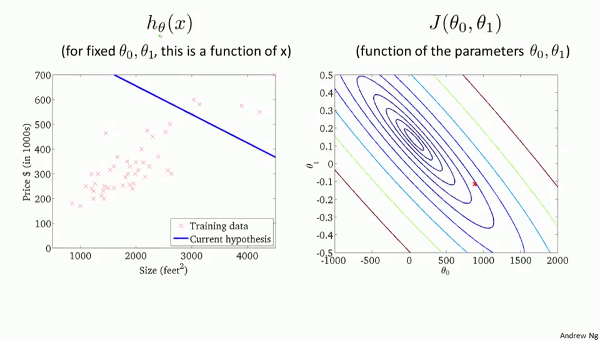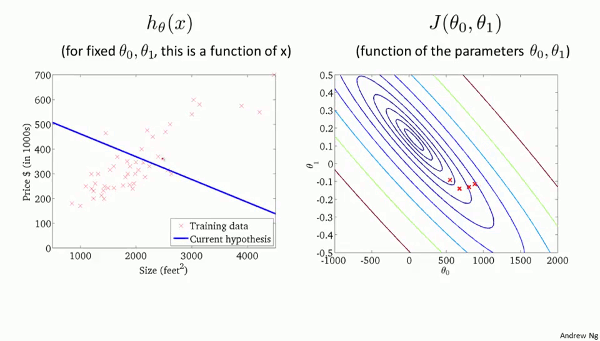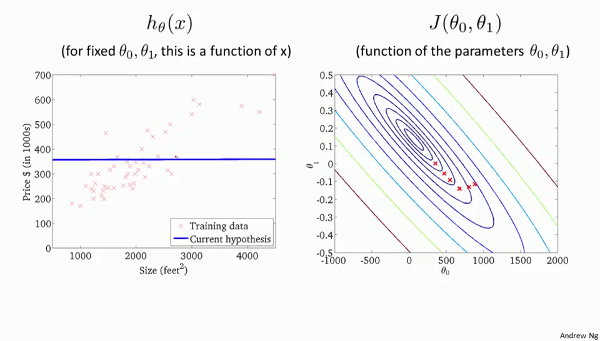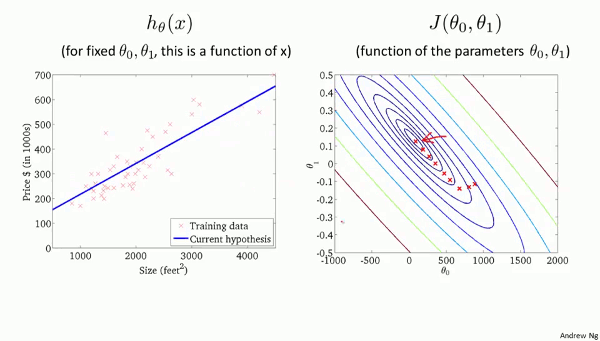
左のグラフで、直線$h_\theta(x)$が
学習データにフィットしていくにしたがって、
ハンモックを2次元に配置した
右の$J(\theta_0, \theta_1)$のグラフで、
赤い点がだんだんと最小値に近づいていきます。
数式的に書くと下のようになります。
その証明まで分からなくても、
この式を、すなおに実行して行けば、
求める予測に到達できますので
分からなくても心配しないで下さい。
Octaveで、
目的関数さえ定義すれば、
複雑そうに見える偏微分の計算も
ほんの数行で書くことができます。
% Gradient decent algorithm
X = [3; 1; 0; 4]; % 入力の定義
y = [2; 2; 1; 3]; % お手本の定義
> theta = [10;10]; % θ0, θ1の定義
> costFunctionJ( X, y, theta) % 目的関数の実行
ans = 9824.8
以下は、興味のある人だけ確認して下さい。
目的関数の偏微分は以下のように表されます。
$$
\begin{matrix}
\frac{\partial}{\partial \theta_j}J(\theta_0, \theta_1)
& = &
\frac{\partial}{\partial \theta_j} \frac{1}{2m}\sum^{m}_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2 \\
& = &
\frac{\partial}{\partial \theta_j} \frac{1}{2m}\sum^{m}_{i=1}(\theta_0 + \theta_1 x^{(i)}-y^{(i)})^2
\end{matrix}
$$
$\theta_0$と$\theta_1$それぞれに対して偏微分すると、
$j=0$ の時は
$\frac{\partial}{\partial \theta_0}J(\theta_0, \theta_1) = \frac{1}{m}(h_\theta(x^{(i)})-y^{(i)})$
$j=1$ の時は、
$\frac{\partial}{\partial \theta_1}J(\theta_0, \theta_1) = \frac{1}{m}(h_\theta(x^{(i)})-y^{(i)}) x^{(i)}$
Gradient decent algorithmでは、
これを収束するまで繰り返していく {
$\theta_0$ := $\theta_0$ - $\alpha$ $\frac{1}{m}$ $\sum^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})$
$\theta_1$ := $\theta_1$ - $\alpha$ $\frac{1}{m}$ $\sum^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})x^{(i)}$
}
これは、以下のようにも書けます。
repeat until convergence {
$\theta_0$ := $\theta_0$ - $\alpha$ $\frac{\partial}{\partial\theta_0} J(\theta)x^{(i)}_0$
$\theta_1$ := $\theta_1$ - $\alpha$ $\frac{\partial}{\partial\theta_1} J(\theta) x^{(i)}_1$
}
### Batch Gradient Decent
最急降下法では、すべての学習データすべてを見て、
直線をフィットさせていきます。
これを**バッチ方式の最急降下法**といいます。
学習データが少ないうちはこの方式でもいいのですが、
データが大量になると、計算量の問題が出てきます。
講座の後半では、この問題を回避する問題も説明されます。





Comments
Post a Comment